Information
Accord’s Library is an archive focused on the works of Yoko Taro. Sadly on October 16th 2024 they made an announcement on discord that they had recived communication from Square Enix and that the site would be taken down on October 31st
Web Archive
I first started off by figuring out how the site worked and checked for any important subdomains. The site consists of:
- https://accords-library.com/ Which is the main website domain
- https://img.accords-library.com/ Which is an image only CDN
- https://gallery.accords-library.com/ Which is a Booru frontend for 6200 posts
- https://resha.re/ Which is a CDN used to store everything other than images
- https://v3.accords-library.com/ Which is a currently in progress beta version of the website
The biggest download here is resha.re totaling just over 350GB of content In total everything is just shy of 400GB
Experimenting
I got to work experimenting on the best way to archive and settled on Browsertrix. It has some quirks but it is by far the best way to archive websites like this.
Main Website
My first attempts ended in failure as certain things wouldnt archive and the archive size was very bloated. I quickly discovered that resha.re isnt very fast and my default timeout on browsertrix wasnt enough however I didnt want to extend this timeout just yet so I blocked all requests to resha.re while archiving the main website so I could come back to it later.
Upon archiving the main website I found out that a few pages wouldnt change content when clicked or wouldnt even be archived at all. Namely the wiki, weapons and video pages along with the cronology page (the wiki “grid view” was also not functional but all of that content was contained in the default view). I added all of these to the archive list manually and restarted the archive only to find the video pages were still broken however the rest of the pages had archived properly. I decided to just remove the videos pages from the archive entirely and redo them at the end.
The Wiki pages still have issues sometimes but when the weapons wiki tab is clicked the original wiki pages become functional again.
Image CDN
Now that I have an archive of the main website and all of its content I need to get media so I started on the image CDN which went quickly and without issue.
Gallery
Gallery posed a second problem as when I archived it every image got archived an extra time according to how many tags it had. For example if an image had 3 tags it would be archived once originally and then once more for each tag it had which was wasting space and time so I threw together some filters to stop any tag query requests which fixed the issue.
Main CDN
Finally came resha.re which has some pretty heavy rate limits and isnt a very fast site to download from so I had to pick my settings carefully, I lowered my threads from 10 down to 2 and increased my timeout to a full day just to make sure no downloads would time out. I decided to make two archives, one with everything other than videos and one with everything. I first ran the non video archive and it took just under two hours to grab everything that wasnt an mp4 file. The full archive with all videos took almost 9 hours.
At this point im left with two archives. One just under 50GB and another around 385GB. The only thing left to add is the video pages.
Video Pages
These pages caused me lots of problems. They would just randomly stop functioning properly for no good reason requiring me to archive multiple times over just to get a working copy. They would even break previous good pages when archived it was very strange and cost me lots of time just re archiving the same pages over and over.
Clean Up
To clean up the pages list and generate the final wacz I decided to archive the homepage of this website.
V3
This is a beta site which is currently unfinished. I decided to put this in its own archive as it doesnt seem to interact with any of the previous CDNs mentioned. Media will not archive properly from this website due to an unknown reason but I don’t think this really matters as the site doesnt contain any exclusive content. This backup contains only the english version of the website.
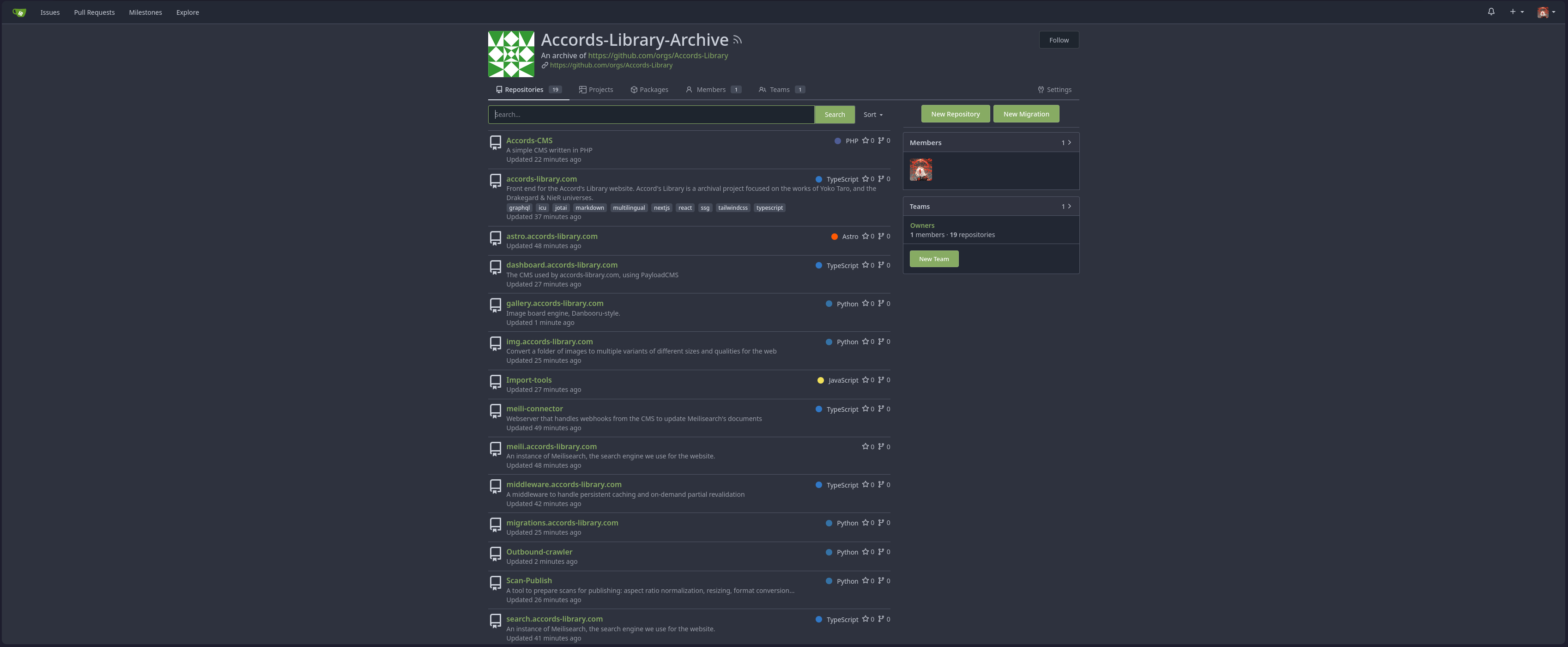
Git Archive
The github was not mentioned in the post but I will be backing it up anyway incase it also vanishes on the 31st
For this I used my own selfhosted gitea instance and just imported all the repos from the organisation. Luckily there were only 19 repos and they werent very large so the import process went quickly and without issue.
Final Overview
FULL
This is the complete Accord’s Library backup totalling 389GB.
It includes:
- Every page from the main website
- Every post from gallery
- Every image from the image CDN
- Every piece of media from the main CDN
It excludes:
- Grid view wiki pages (This content already exists within the standard wiki view)
NOVIDEO
This is a mostly complete Accord’s Library backup totalling 47GB
It includes:
- Every page from the main website
- Every post from gallery
- Every image from the image CDN
- Almost all media from the main CDN
It excludes:
- Any file with a .mp4 extension from resha.re
- Grid view wiki pages (This content already exists within the standard wiki view)
SMALL
This is a very small and basic Accord’s Library backup. It is only 2.8GB. This version is designed to be shared easily and contains most important things from the website other than video and audio files
It includes:
- Almost every page from the main website
- Every image from the image CDN
It excludes:
- All video pages from the main website
- Every post from gallery
- All media from the main CDN
V3
This is a basic backup of the Accord’s library v3 beta site totalling just under 1GB
It includes:
- Every text page from the main website
It excludes:
- All media from v3
- All non english pages
The Release
The release was coordinated through the Drakenier discord server run by mint See this tweet for the link to the release